一、正则的基本概念
1. 字符串的一般操作
测试文件 # imooc.txt
imooc javaimooc Htmlimooc Python imooccc#go
查询特定字符
# string_find.py def find_start_imooc(fname): f = open(fname) for line in f: if line.startswith('imooc'): print(line)find_start_imooc('imooc.txt')def find_in_imooc(fname): f = open(fname) for line in f: if line.startswith('imooc')\ and line[:-1].endswith('imooc'): print(line)find_in_imooc('imooc.txt') 输出
imooc javaimooc Htmlimooc Python imoocimooc Python imooc
2.使用正则
像上面那样,每次都需要做一个函数去解析字符串很麻烦,于是考虑做成一个简单的规则。使用单个字符串来描述符合某个语法规则的字符串
二、正则表达式的使用
1.流程图
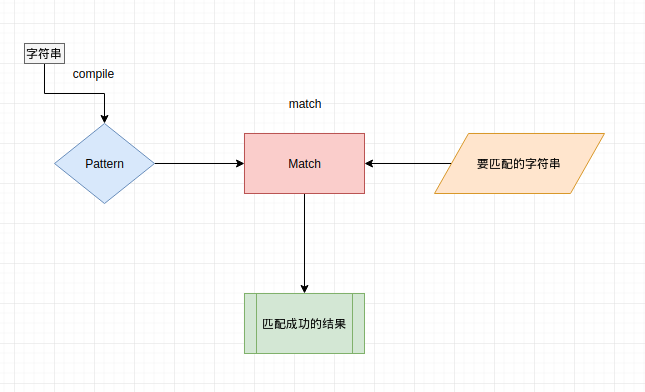
使用正则
# re_find.pyimport repa = re.compile(r'imooc', re.I)with open('imooc.txt') as f: for line in f: if pa.match(line): print(line) 输出
imooc javaimooc Htmlimooc Python imooc
注意:也可以使用使用 match
ma = re.match(r'imooc','imooC python', re.I)print(ma.group())
输出
imooC
三、正则表达式的语法(参考 http://www.runoob.com/python/python-reg-expressions.html)
模式
| 模式 | 描述 |
|---|---|
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾。 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
| [...] | 用来表示一组字符,单独列出:[amk] 匹配 'a','m'或'k' |
| [^...] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
| re* | 匹配0个或多个的表达式。 |
| re+ | 匹配1个或多个的表达式。 |
| re? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
| re{ n} | |
| re{ n,} | 精确匹配n个前面表达式。 |
| re{ n, m} | 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
| a| b | 匹配a或b |
| (re) | G匹配括号内的表达式,也表示一个组 |
| (?imx) | 正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域。 |
| (?-imx) | 正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域。 |
| (?: re) | 类似 (...), 但是不表示一个组 |
| (?imx: re) | 在括号中使用i, m, 或 x 可选标志 |
| (?-imx: re) | 在括号中不使用i, m, 或 x 可选标志 |
| (?#...) | 注释. |
| (?= re) | 前向肯定界定符。如果所含正则表达式,以 ... 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。 |
| (?! re) | 前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功 |
| (?> re) | 匹配的独立模式,省去回溯。 |
| \w | 匹配字母数字及下划线 |
| \W | 匹配非字母数字及下划线 |
| \s | 匹配任意空白字符,等价于 [\t\n\r\f]. |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于 [0-9]. |
| \D | 匹配任意非数字 |
| \A | 匹配字符串开始 |
| \Z | 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。c |
| \z | 匹配字符串结束 |
| \G | 匹配最后匹配完成的位置。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
| \n, \t, 等. | 匹配一个换行符。匹配一个制表符。等 |
| \1...\9 | 匹配第n个分组的内容。 |
| \10 | 匹配第n个分组的内容,如果它经匹配。否则指的是八进制字符码的表达式。 |
修饰符
| 修饰符 | 描述 |
|---|---|
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.S | 使 . 匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B. |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。 |
四、正则表达式的实例
1. 字符匹配
| 实例 | 描述 |
|---|---|
| python | 匹配 "python". |
2. 字符类
| 实例 | 描述 |
|---|---|
| [Pp]ython | 匹配 "Python" 或 "python" |
| rub[ye] | 匹配 "ruby" 或 "rube" |
| [aeiou] | 匹配中括号内的任意一个字母 |
| [0-9] | 匹配任何数字。类似于 [0123456789] |
| [a-z] | 匹配任何小写字母 |
| [A-Z] | 匹配任何大写字母 |
| [a-zA-Z0-9] | 匹配任何字母及数字 |
| [^aeiou] | 除了aeiou字母以外的所有字符 |
| [^0-9] | 匹配除了数字外的字符 |
3. 特殊字符类
| 实例 | 描述 |
|---|---|
| . | 匹配除 "\n" 之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用象 '[.\n]' 的模式。 |
| \d | 匹配一个数字字符。等价于 [0-9]。 |
| \D | 匹配一个非数字字符。等价于 [^0-9]。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \w | 匹配包括下划线的任何单词字符。等价于'[A-Za-z0-9_]'。 |
| \W | 匹配任何非单词字符。等价于 '[^A-Za-z0-9_]'。 |
五、正则表达式中的贪婪模式及分组
贪婪模式: '*', '+', and '?' 默认是贪婪匹配,可以在后面加 ? 变成非贪婪匹配。
分组:可以使用() 与 \number,进行匹配分组
# re_group.pyma = re.match(r'<(\w+)>.* ', 'Python Java ')print(ma.group())ma = re.match(r'<(\w+)>.*? ', 'Python Java ')print(ma.group())
输出
Python Java Python
六、re 模块的其它方法
因为 match 方法是从头开始匹配的。如果在整个字符串中查找,使用 match就不太合适了。
1. search 方法
# re_search.pyimport resm = re.search(r'\d+', 'imooc videonum=1000')print(sm.group())
输出
1000
2. findall 方法
# re_findall.pyimport reresult_list = re.findall(r'\d+', 'c++=100, java=90, python=80')print(result_list)
输出
['100', '90', '80']
3. 注意: search 和 findall方法进行查询时,会对每个字符进行查询,如果未查到则返回空 '', 比如
result_list = re.findall(r'\d*', 'c++=100, java=90, python=80')print(result_list)
输出
['', '', '', '', '100', '', '', '', '', '', '', '', '90', '', '', '', '', '', '', '', '', '', '80', '']
4. sub 方法
# re_sub.pystr1 = 'Imooc Python 3000'result = re.sub(r'\d+', lambda x : str(int(x.group()) + 1), str1)print(result)
输出
Imooc Python 3001
5. split 方法
str2 = 'Python Java C Golang'items = re.split(r'\W+', str2)print(items)
输出
['Python', 'Java', 'C', 'Golang']
七、抓取图片的示例
# search_pic.pyimport urllib3import rehttp = urllib3.PoolManager()# 1: site urlreq = http.request('GET', 'http://www.imooc.com/course/list')content = req.data.decode('utf-8')# 2: picture urlslisturl = re.findall(r'src=.+\.jpg', content)pic_url_list = map(lambda x : x[:4], listurl)# 3: write picturesi = 0for url in pic_url_list: # open as a binary file f = open(str(i)+ '.jpg', 'wb') f.write(http.request('GET', url).data) f.close() i += 1